Mapping Halifax Traffic Calming Requests
Mar 03, 2021
Halifax has a systemic road safety problem. One way it manifests is people driving too fast, especially on residential streets.
Recently, Halifax Regional Council mostly approved their 2021 capital budget. It includes $1 million for traffic calming and the final budget may include $1 million more. Read more about that here or here.
The city publishes a ranked list of approved requests. Not all requests are approved due to rules that contribute to the systemic problem. Even so, as of the last update on November 27, 2020, there are 282 approved requests.
The list contains entries like this:
| Ranking | Street Name | From | To | District |
|---|---|---|---|---|
| 1 | Maple St | Thistle St | Ochterloney St | 5 |
| 2 | Buckingham Dr | Windsor Dr | Penny Ln | 13 |
| 3 | Ingram Dr | Winley Dr | Lexington Ave | 1 |
| 4 | Lakeview Ave | Sackville Dr | end | 14 |
| 31 | Poplar Dr | all | 4 |
Unfortunately, there’s no associated map.
After the recent budget news, Bill at Walk ’n’ Roll Halifax emailed me suggesting how nice it would be if the requests were visible on a map. It sounded like a fun data wrangling project so I decided to give it a go.
My goal was a custom Google My Maps map with a line for each entry. On Maple St, for example, I wanted a line from Thistle St to Ochterloney St. For Poplar Dr, the entire street would have a line.
Lines could be drawn manually in Google My Maps but that would be very tedious for 10 or fewer entries, let alone 282. There had to be a better way!
I was working on a different project recently and came across the Street Centrelines dataset in the Halifax Open Data Catalogue.
This dataset contains an entry for each street segment in Halifax. It’s available in Keyhole Markup Language (KML), an XML-based format for sharing map data. Google My Maps can also import KML.
Here’s a summary of how the entries look for Maple St:
| FDMID | ROUTE_ID | FULL_NAME | FROM_STR | TO_STR | DIRECTION | Line String |
|---|---|---|---|---|---|---|
| 200000543 | 2633 | MAPLE ST | ROSE ST | THISTLE ST | BOTH | (-63.56847119, 44.6728361400001) … |
| 200000544 | 2633 | MAPLE ST | TULIP ST | ROSE ST | BOTH | (-63.5676338499999, 44.6723266400001) … |
| 200000545 | 2633 | MAPLE ST | DAHLIA ST | TULIP ST | BOTH | (-63.566795656, 44.6718060790001) … |
| 200000548 | 2633 | MAPLE ST | MYRTLE ST | DAHLIA ST | BOTH | (-63.5659460969999, 44.6712820830001) … |
| 200000549 | 2633 | MAPLE ST | OCHTERLONEY ST | MYRTLE ST | BOTH | (-63.564231025, 44.670224235) … |
FDMID is a unique ID assigned to each segment. ROUTE_ID groups segments by street. This example shows all Maple St segments have ROUTE_ID 2633. DIRECTION indicates how vehicles are meant to move on the segment. BOTH indicates 2-way travel.
The line string data gives a list of longitude, latitude pairs that can be used to trace that segment’s path on a map.
For example, using geojson.io to map the line string for the Tulip St to Dahlia St segment looks like this:
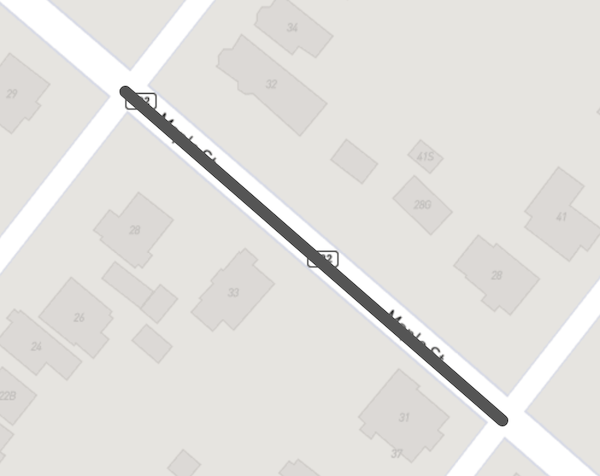
Maple St segment
If I could turn the traffic calming request entries into their related segments, mapping the requests seemed possible!
Looking at the list of requests, there were three types:
- Both From and To specified (like Maple St)
- From specified, To listed as “end” (like Lakeview Ave)
- From listed as “all”, to indicate the entire street (like Poplar Dr)
This got me thinking about a process like this for each request:
- Find a start segment given the street name and using From if specified
- Find an end segment with the same ROUTE_ID as the start segment, using To if specified
- Find the list of segments from the start segment to the end segment
I figured there would also need to be some manual tweaking along the way. For example, there are three different Maple Streets in Halifax. Having Thistle St and Ochterloney St specified as From and To would probably make it unique enough but it was something to be aware of.
My next step was to get the data into SQLite, my database of choice for projects like this.
Importing the Street Centrelines data was pretty straightforward since it’s structured. You can see a sample of what that process looked like here.
The request list, on the other hand, took a bit more work. It’s a PDF, maybe a of a Word document. Copying the tables and pasting into various places (Google Sheets, a text editor, etc) didn’t work. I ultimately had to use pdftotext and some post-processing. This pipeline did most of the work:
pdftotext -simple street-calming-ranked-2020-11.pdf - | \
ruby -lpe 'next unless $_ =~ /^\s+\d/;
$_.sub!(/^\s+/, "");
$_.gsub!(/\s{2,}/, "\t")'
That selected all the lines beginning with a number (the rank), cut leading space, then replaced all multiple spaces with a tab. That got the list mostly into a nice tab-separated file but there were still a couple bits that had to be fixed manually.
With both sets of data in SQLite, the real fun could begin!
The first step in the process above is finding a start segment. Using the Maple St example, a query like this might work:
> select id, route_id, full_name, from_str, to_str, direction
from segments where full_name='MAPLE ST' and from_str='THISTLE ST';
But this returns no rows. What about checking to_str?
> select id, route_id, full_name, from_str, to_str, direction
from segments where full_name='MAPLE ST' and to_str='THISTLE ST';
id route_id full_name from_str to_str direction
--------- -------- --------- -------- ---------- ---------
200000543 2633 MAPLE ST ROSE ST THISTLE ST BOTH
Okay! I realized that the Street Centrelines notion of “from” and “to” may not match up with the calming requests'.
This gives a starting segment for the Maple St request: 200000543. This also shows the ROUTE_ID as 2633.
Continuing with the process above, the next step would be to find an end segment on the same route. Here’s what that looks like:
> select id, route_id, full_name, from_str, to_str, direction
from segments where route_id=2633 and 'OCHTERLONEY ST' in (from_str, to_str);
id route_id full_name from_str to_str direction
--------- -------- --------- -------------- --------- ---------
200000549 2633 MAPLE ST OCHTERLONEY ST MYRTLE ST BOTH
This query uses 'OCHTERLONEY ST' in (from_str, to_str) to look for Ochterloney in the segment’s FROM_STR or
TO_STR. Similar to searching for Thistle St, the found segment has Ochterloney as “from,” which is reversed from the
request.
This gives an ending segment to pair with the start: 200000549.
Now, how about finding a path between them? This was shaping up to be a graph traversal problem which I’ve enjoyed as part of Advent of Code.
Walking through the Maple St segments will show this in action. Here are all the Maple St segments again:
| id | route_id | full_name | from_str | to_str | direction |
|---|---|---|---|---|---|
| 200000543 | 2633 | MAPLE ST | ROSE ST | THISTLE ST | BOTH |
| 200000544 | 2633 | MAPLE ST | TULIP ST | ROSE ST | BOTH |
| 200000545 | 2633 | MAPLE ST | DAHLIA ST | TULIP ST | BOTH |
| 200000548 | 2633 | MAPLE ST | MYRTLE ST | DAHLIA ST | BOTH |
| 200000549 | 2633 | MAPLE ST | OCHTERLONEY ST | MYRTLE ST | BOTH |
Beginning with the starting segment 200000543 (ROSE ST to THISTLE ST), it seems two steps are possible:
- Moving to a segment where
to_str='ROSE ST', if one exists - Moving to a segment where
from_str='THISTLE ST, if one exists
According to the list, there is no segment where from_str='THISTLE ST'. This makes sense as Maple St ends at Thistle
St.
There is a segment where to_str='ROSE ST', however: 200000544 (TULIP ST to ROSE ST). Repeating the same process leads
to 200000545 (DAHLIA ST to TULIP ST), 200000548 (MYRTLE ST to DAHLIA ST), and finally:
200000549 (OCHTERLONEY ST to MYRTLE ST)
This means the segments needed for the “Maple St from Thistle St to Ochterloney St” request are:
- 200000543 (ROSE ST to THISTLE ST)
- 200000544 (TULIP ST to ROSE ST)
- 200000545 (DAHLIA ST to TULIP ST)
- 200000548 (MYRTLE ST to DAHLIA ST)
- 200000549 (OCHTERLONEY ST to MYRTLE ST)
Taking the line string of each segment and plotting them on the map covers the entire street:
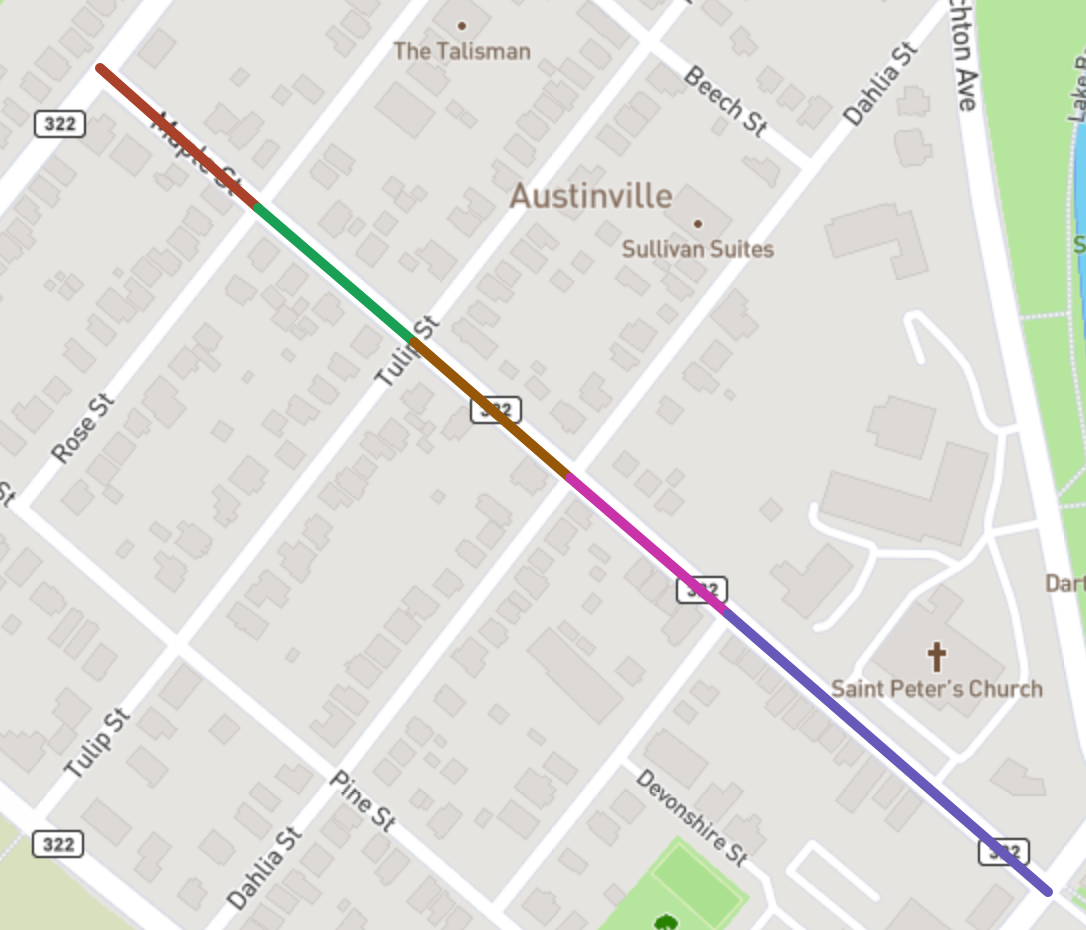
Maple St segments
(Thinking about it now, it’s not clear why the request wasn’t “Maple St (all)”)
I started with this approach but it fell over for a few reasons.
Consider the Ingram Dr request. Here are all the segments for Ingram Dr:
| id | from_str | to_str | direction |
|---|---|---|---|
| 100000840 | NEWPORT DR | DEVONPORT AVE | BOTH |
| 100000844 | CANTERBURY LANE | NEWPORT DR | BOTH |
| 100000861 | END | BOTH | |
| 100001603 | WATERFORD CRES | CANTERBURY LANE | BOTH |
| 100001954 | DEVONPORT AVE | WINLEY DR | BOTH |
| 100001955 | WINLEY DR | END | BOTH |
| 100002542 | CANTERBURY LANE | LEXINGTON AVE | BOTH |
| 100002544 | WATERFORD CRES | JOSLYN DR | BOTH |
| 100002546 | JOSLYN DR | LINCOLNSHIRE DR | BOTH |
| 100002547 | LINCOLNSHIRE DR | LEXINGTON AVE | BOTH |
First up, there are multiple possible starting segments: should 100001954 (DEVONPORT AVE to WINLEY DR) be used or 100001955 (WINLEY DR to END)? It may be clear that DEVONPORT AVE to WINLEY DR is a better choice since the other option goes to the end of the street. But both should be considered.
Next, there are also multiple possible ending segments! Should 100002542 (CANTERBURY LANE to LEXINGTON AVE) be used or 100002547 (LINCOLNSHIRE DR to LEXINGTON AVE)? It’s not as clear which is a better choice as with the starting segment.
On top of all that, the process used for Maple St of stepping between segments based on FROM_STR/TO_STR breaks down: there are multiple segments involving CANTERBURY LANE. It may be tempting to skip to 100002542 (CANTERBURY LANE to LEXINGTON AVE) since it involves the To portion of the request (Lexington Ave), but that would miss a portion of the street.
There’s also a segment with a blank FROM_STR.
I fixed the first two problems by letting the process work with multiple start and end segments and trimming the path. Consider these segments:
| id | from_str | to_str |
|---|---|---|
| 1 | First St | Second St |
| 2 | Second St | Third St |
| 3 | Third St | Fourth St |
| 4 | Fourth St | Fifth St |
If the goal is finding segments between Second St and Fourth St, the process could start with segment 1 or 2 and end with 3 or 4. Including segments 1 or 4 on the map would not be desired, though, since they are outside the goal.
Changing the process to stop after stepping to any acceptable end segment (3 in this case) ensured segment 4 would not be included. Returning segment 1 was fixed by ensuring returned paths only started with a single acceptable start segment.
The blank FROM_STR required a new approach for stepping through segments.
Recall each segment has a line string with a list of coordinates needed to draw that segment on a map. Instead of using FROM_STR and TO_STR to move between segments, how about involving that?
I changed my data loading process to pull out the first and last points of each segment’s line string and save them to new columns. Revisiting the Ingram Dr segments above, here’s what they looked like with first and last points:
| id | from_str | to_str | first_point | last_point |
|---|---|---|---|---|
| 100000840 | NEWPORT DR | DEVONPORT AVE | (-63.62227216, 44.7916761270001) | (-63.621533658, 44.7901758950001) |
| 100000844 | CANTERBURY LANE | NEWPORT DR | (-63.6242073449999, 44.7942227140001) | (-63.62227216, 44.7916761270001) |
| 100000861 | END | (-63.6227061989999, 44.8046496360001) | (-63.622992873, 44.803319151) | |
| 100001603 | WATERFORD CRES | CANTERBURY LANE | (-63.626087088, 44.7960596870001) | (-63.6242073449999, 44.7942227140001) |
| 100001954 | DEVONPORT AVE | WINLEY DR | (-63.621533658, 44.7901758950001) | (-63.622156326, 44.7864079710001) |
| 100001955 | WINLEY DR | END | (-63.622156326, 44.7864079710001) | (-63.620607606, 44.784540276) |
| 100002542 | CANTERBURY LANE | LEXINGTON AVE | (-63.622992873, 44.803319151) | (-63.624091294, 44.800912871) |
| 100002544 | WATERFORD CRES | JOSLYN DR | (-63.626087088, 44.7960596870001) | (-63.6259402429999, 44.7988730810001) |
| 100002546 | JOSLYN DR | LINCOLNSHIRE DR | (-63.6259402429999, 44.7988730810001) | (-63.624940983, 44.799972456) |
| 100002547 | LINCOLNSHIRE DR | LEXINGTON AVE | (-63.624940983, 44.799972456) | (-63.624091294, 44.800912871) |
While the points are a bit unwieldy to look at, they seemed to be an improvement. For example, it’s clearer now (to the process) that the segments from Winley Dr to Lexington Ave should be:
- 100001954 (DEVONPORT AVE to WINLEY DR) first point leads to last point of
- 100000840 (NEWPORT DR to DEVONPORT AVE) first point leads to last point of
- 100000844 (CANTERBURY LANE to NEWPORT DR) first point leads to last point of
- 100001603 (WATERFORD CRES to CANTERBURY LANE) first point leads to first point of
- 100002544 (WATERFORD CRES to JOSLYN DR) last point leads to first point of
- 100002546 (JOSLYN DR to LINCOLNSHIRE DR) last point leads to first point of
- 100002547 (LINCOLNSHIRE DR to LEXINGTON AVE)
Another twist is the step from 100001603 to 100002544 involving two first points.
Next up: Agricola St!
One of the requests is: Agricola St from Duffus St to Young St
This portion of Agricola St has a boulevard:
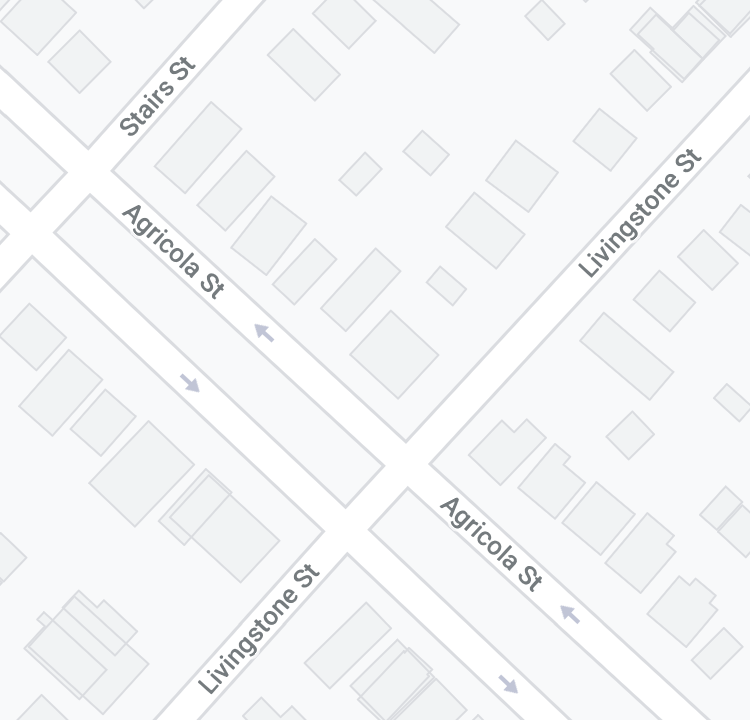
Agricola and Livingstone intersections
In the segment data, the Livingstone St segments look like this:
| id | from_str | to_str | direction |
|---|---|---|---|
| 300000517 | LIVINGSTONE ST | STAIRS ST | FOTD |
| 300000535 | KANE ST | LIVINGSTONE ST | FOTD |
| 700005048 | STAIRS ST | LIVINGSTONE ST | FOTD |
| 700005049 | LIVINGSTONE ST | KANE ST | FOTD |
Notice that direction here is FOTD instead of BOTH. FOTD stands from “From Origin To Destination,” meaning the first segment 300000517 (LIVINGSTONE ST to STAIRS ST) is meant for travel only from Livingstone St to Stairs St. The third segment 700005048 (STAIRS ST to LIVINGSTONE ST) is meant for travel only from Stairs St to Livingstone St.
Here, direction matters. Instead of looking for a next segment based only on first/last point, the directions of both the current segment and the possible next segment must be considered. Consider the transition from Young St (with direction BOTH to the boulevard area where segments have direction FOTD):
| id | from_str | to_str | direction | first_point | last_point |
|---|---|---|---|---|---|
| 300000586 | DEMONE ST | YOUNG ST | BOTH | (-63.600420401, 44.660267762) | (-63.601034291, 44.6606932450001) |
| 300000573 | YOUNG ST | KAYE ST | FOTD | (-63.601034291, 44.6606932450001) | (-63.6013933099999, 44.660891484) |
| 700005052 | KAYE ST | YOUNG ST | FOTD | (-63.6013933099999, 44.660891484) | (-63.601034291, 44.6606932450001) |
The last point of 300000586 (DEMONE ST to YOUNG ST) matches the first point of both 300000573 (YOUNG ST to KAYE ST) and the last point of 700005052 (KAYE ST to YOUNG ST). However, since 700005052 has direction FOTD, it shouldn’t be considered as a segment to get from Young St to Kaye St.
I built up a table to describe the current/next direction possibilities and how next segments should be considered:
| Current Direction | Next Direction | How to match |
|---|---|---|
| BOTH | BOTH | current first point or last point equals next first point or last point |
| BOTH | FOTD | current first point or last point equals next first point |
| FOTD | FOTD | current last point equals next first point |
| FOTD | BOTH | current last point equals next first point or last point |
This worked well! Point matching and direction consideration let the process satisfy the Agricola request.
The point matching was based entirely on string/text equality and not any math. My hope was that points were exact enough for this to work. It mostly was but eventually broke down a bit for a couple reasons:
- Some segment transitions had tiny (< 1 meter) distances between their first/last points which broke string equality
- Some streets just don’t follow a contiguous path!
For the tiny distance differences, I did end up using a point distance calculation which considered distances less than a meter as being “equal.”
An example of the second reason is Jamieson St in Dartmouth:
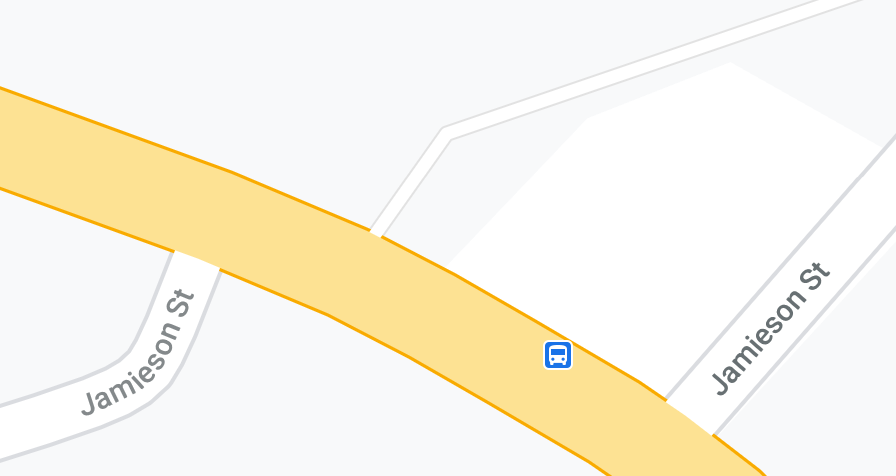
Jamieson St and Windmill Rd intersections
It connects to Windmill Rd in two different places.
For the Jamieson St and other oddities I could have probably spent a lot of time on, I resorted to manual intervention.
As I worked on this process, I tried to keep parts of the process decoupled. For example, the code to find a path between segments didn’t care how the “from” and “to” segments were found. Similarly, the code to find the “from” segments didn’t care how the path was found.
This gave me chances to hook in just enough manually-sourced information to help the process along.
Consider this request: Eisener Blvd from Portland Estates Blvd West to Portland Lakes Trail
In this case, “Portland Lakes Trail” is not a street, it’s this trail crossing:
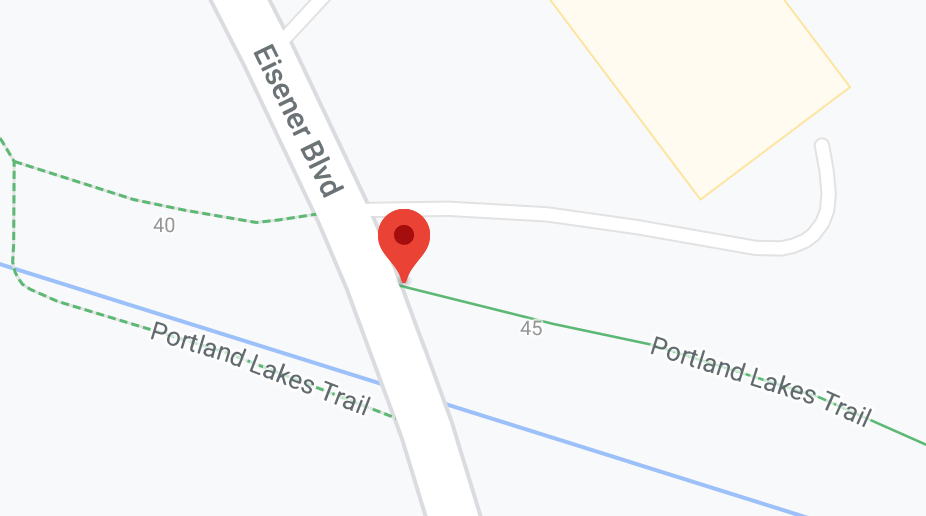
Eisener Blvd and Portland Lakes Trail intersection
The “end segment” discovery part of the system would not be able to find a match for “Portland Lakes Trail” in the Street Centrelines data. In this case, I needed to tell the process explicitly what end segment to use.
I searched the Centrelines data and the map and found an acceptable fallback end segment: 200002793 (NORM NEWMAN DR to RUSSELL LAKE DR).
While the process up to this point was driven by data in the SQLite database, I added support for “override files” so I could continue to rebuild the database if I needed to change the schema.
With override file support, telling the system to use as the end segment meant writing 200002793 to a file named
overrides/10.end.
The filename 10.end meant for request with rank 10, when searching for an end segment, use 200002793 instead of trying
to find a match in the Centrelines data.
I added similar support for N.start for specifying a start segment and N.route for listing segments to satisfy a
request.
In the end, I had to create 67 start files, 59 end files, and 2 route files. 29 requests needed both start and
end files.
Once the process could satisfy all requests it was time to export for mapping. I used a Go package to generate the KML. Color-coding by rank helped make nearby requests more distinct while also showing many streets have multiple requests.
Here’s how it ended up looking:
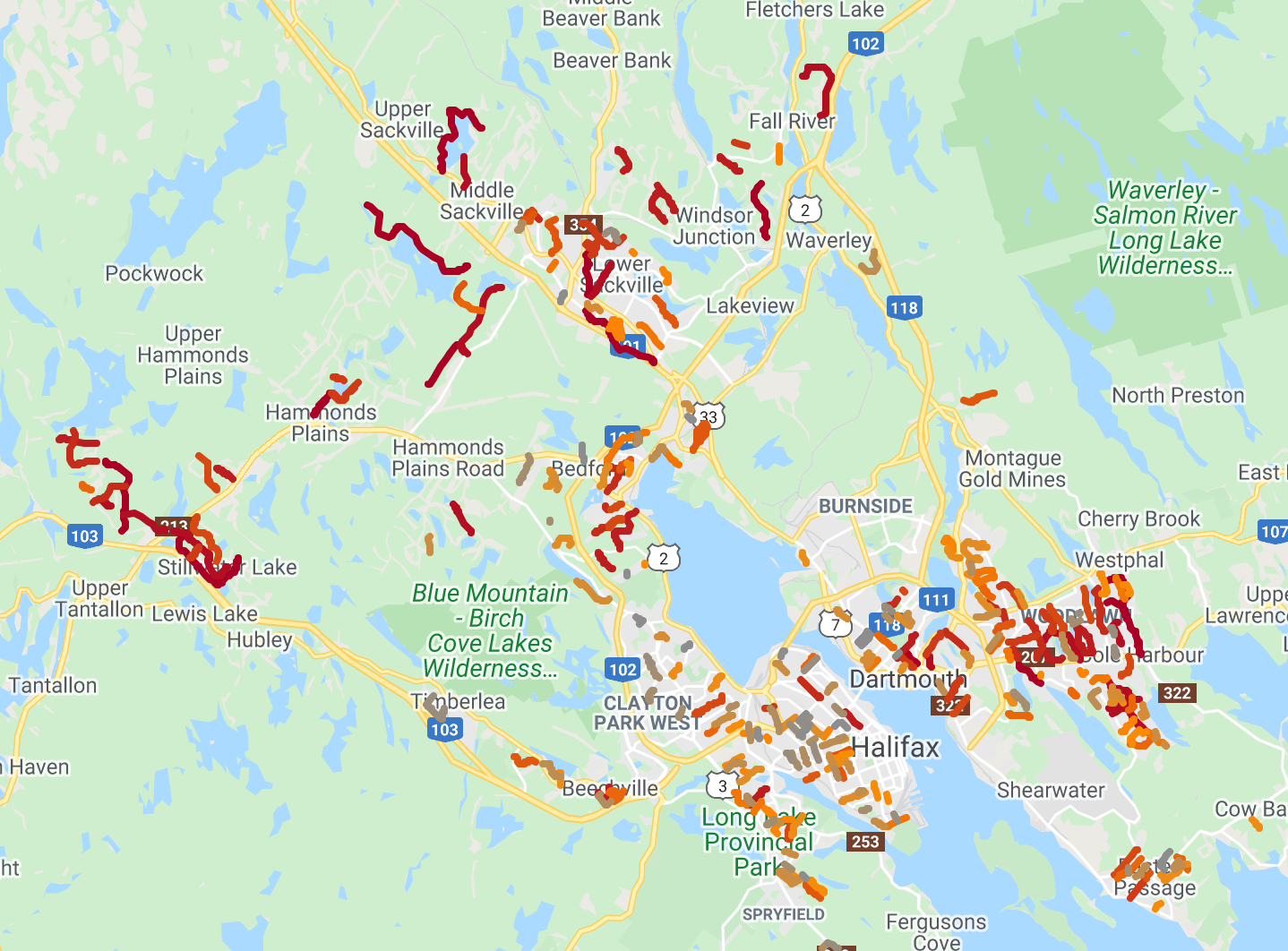
Completed map
You can view the interactive map here.
If you like, you can also browse the code here.
This was a fun project. I really enjoy the process of discovery and iteration that comes with combining data like this. And since it was my first time using the Street Centrelines data I learned a bunch. That will help me next time I’d like to use it!
At the same time, I wish this project hadn’t been necessary. It’s likely Halifax staff have this information in an internal Geographic information system, probably with a map. A map like the one I’ve produced here should really be in the Halifax Open Data Catalogue alongside the Street Centrelines data.
Until then, we have this map!